
使用场景一 车载
针对车载场景的噪声环境进行了优化,尤其是车载高频场景如接听电话、开关车窗、广播音乐、路线导航等进行了语音数据训练,提供车载场景的高准确度语音识别结果。

通用解决方案
大众问问可提供多场景、多语言、多垂类的AI能力,赋能于各行各业

DSP
声学前端
ASR
语音识别
SWYS
所见即可说
TTS
语音合成
VC
声音克隆
声学前端
回声消除
噪音抑制
纯净人声
回声消除
通过采集回声的样本,与原始的采样进行比较,移除回声。可消除mic(单Mic、双Mic、4Mic)录入的设备本身播放的音乐TTS播报声等,只保留说话人声音

带回声的语音

处理后的语音
噪声抑制
用于消除背景噪声,改善语音信号的信噪比和可懂度,让人和机器听得更清楚。针对胎噪、风噪、车辆震动等噪声环境进行模型优化,可直接通过频率筛选过滤掉噪音,提供高质量的过滤效果。

带噪声的语音

处理后的语音
纯净人声
通过训练端到端的模型,实现忽略原始音频的所有背景噪音,对人声特征提取
带背噪的语音
处理后的语音
在线试用
支持文件上传的方式进行声学前端处理,支持回声消除、噪声抑制、纯净人声,支持20M以内的WAV格式
处理内容
请在此处上传麦克风信号文件,拖拽到此处或点击选择文件
请在此处上传参考信号文件,拖拽到此处或点击选择文件
语音识别
全面应用学界领先的端到端(CTC)语音识别框架、断点检测(VAD)技术,采用增强学习、迁移学习等方法,融合多项学界及业界领先的技术,核心研发团队经过大量的研究、实践和迭代积累,使16K采样率的语料识别准确度可达98%,8K采样率,训练后,识别准确率可达90%以上。

使用场景一 车载
针对车载场景的噪声环境进行了优化,尤其是车载高频场景如接听电话、开关车窗、广播音乐、路线导航等进行了语音数据训练,提供车载场景的高准确度语音识别结果。

使用场景二 客服
适用于智能客服中的语音识别需求,可以提供售前咨询、售后服务以及录音质检等场景的精准识别。大幅提升客服工作的工作质量。

使用场景三 智能硬件
针对家居场景相关的控制做识别优化,在语音识别上更加灵活,在家电控制、场景控制、模式切换等都做了相应的适配优化,用户用起来更省心。
在线转换
文件转文字仅支持20M以内的WAV格式;在线语音转文字仅支持12秒
所见即可说
支持用户在应用的不同界面使用语音交互时,直接说出当前页面上的文字元素或一些通用的触控指令,如放大缩小、翻页跳转等。
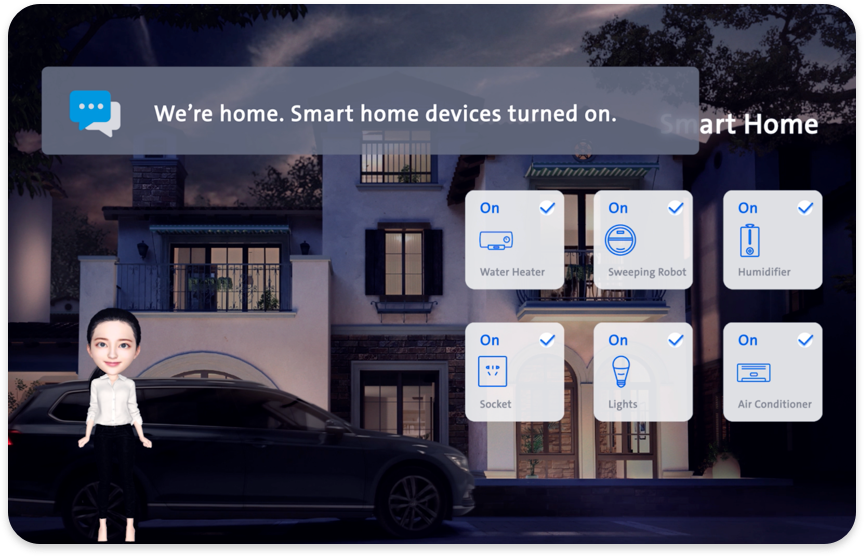
Onboard 场景
直接通过“打开设置”、“我的车辆”、“空调设置”等命令,唤醒车身设置或空调界面。在相应界面通过屏幕上关键字,或者“上一页”、“向下翻”等语音对话来控制菜单页面,实现音量调节、屏幕亮度调节、设备连接、各种功能开关、车身控制、以及空调调节等需要手动点击完成的操作。
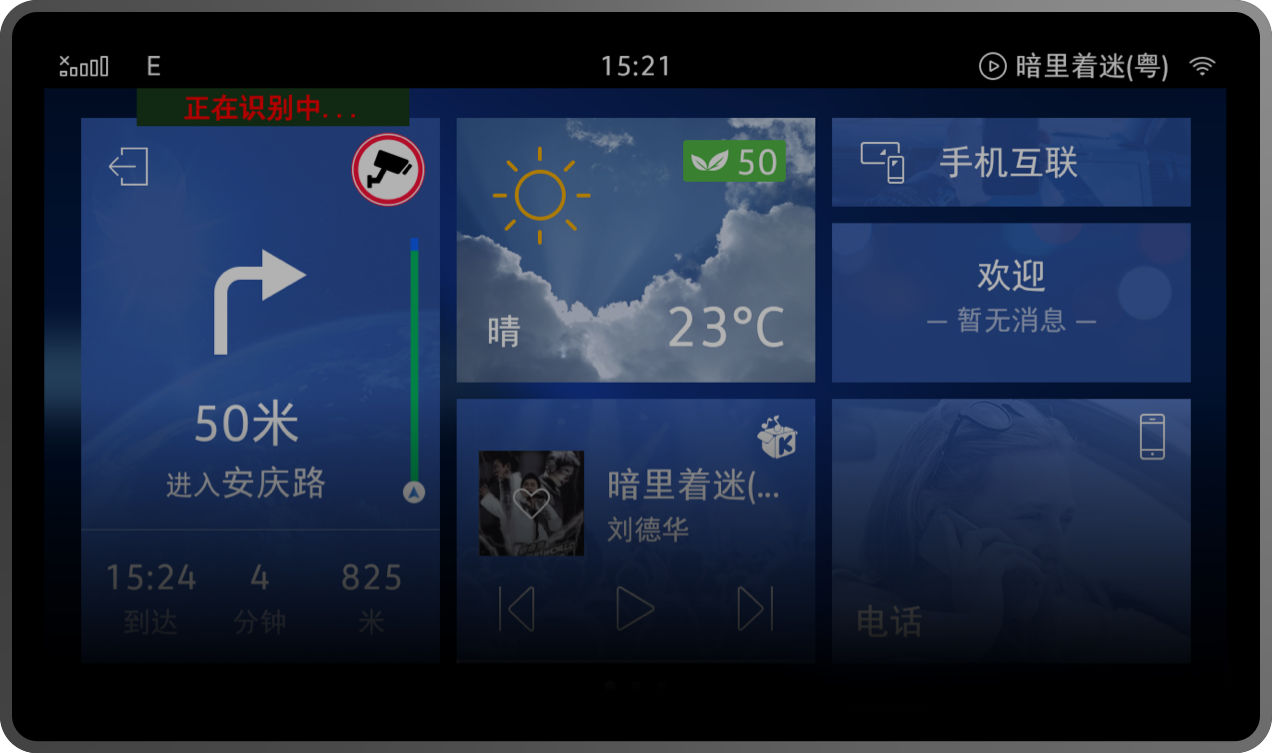
Navi 场景
简单的几个语音指令,即可完成导航设置、路线查询与选择、地图控制等功能。
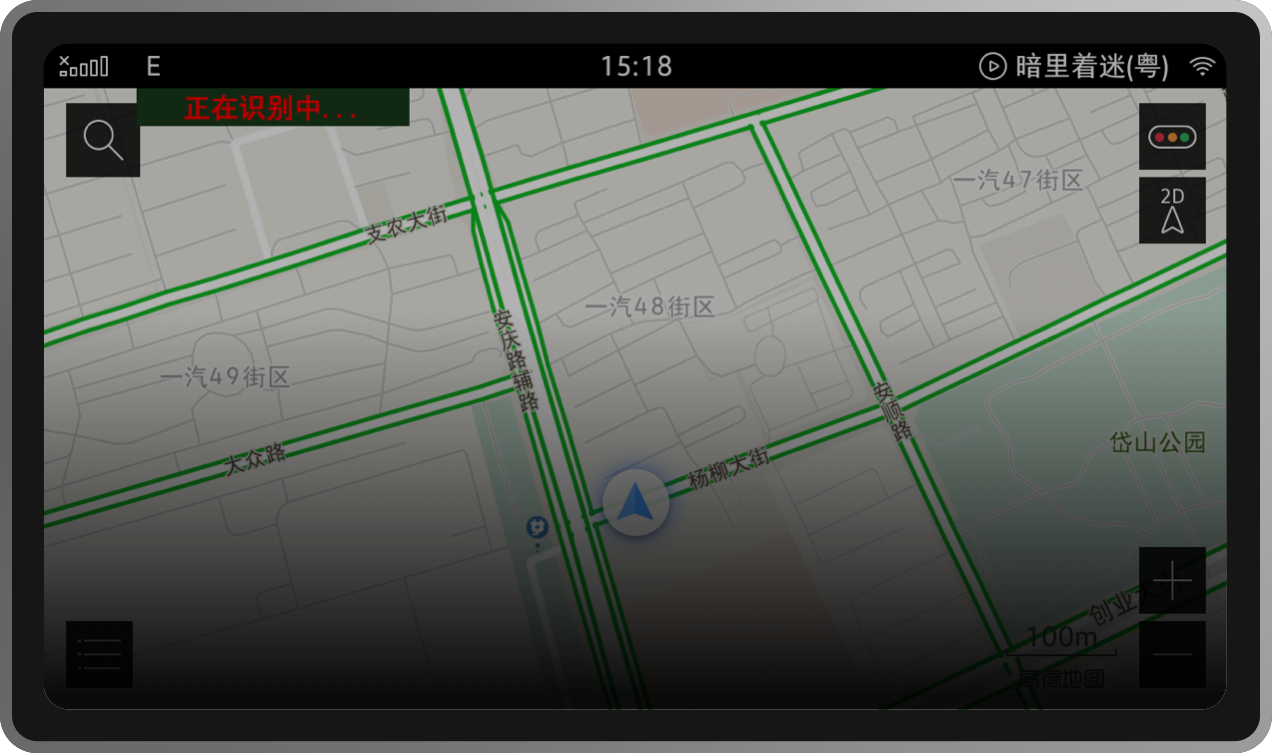
3rd_Apps 场景
语音控制第三方应用,整合车内生态智能体系。真正使车主从安全驾驶层面达到“手不离舵,眼不离路”的沉浸式驾驶体验。
语音合成
全面应用学界领先的端到端(CTC)语音识别框架、断点检测(VAD)技术,采用增强学习、迁移学习等方法,融合多项学界。
试用产品
xinyi-女声
angela-女声
